浏览器存储机制
通过网络获取内容既速度缓慢又开销巨大。较大的响应需要在客户端与服务器之间进行多次往返通信,这会延迟浏览器获得和处理内容的时间,还会增加访问者的流量费用。因此,缓存并重复利用之前获取的资源的能力成为性能优化的一个关键方面。
浏览器缓存机制有四个方面,按获取资源请求时的优先级依次排序
Memory Cache
Service Worker Cache
HTTP Cache(最重要缓存策略)
Push Cache
HTTP缓存机制
HTTP 缓存是我们日常开发中最为熟悉的一种缓存机制。它又分为强缓存和协商缓存。优先级较高的是强缓存,在命中强缓存失败的情况下,才会走协商缓存。
强缓存
expires:expires: Wed, 11 Sep 2019 16:12:18 GMTexpires 是一个绝对的时间戳,接下来如果我们试图再次向服务器请求资源,浏览器就会先对比本地时间和 expires 的时间戳,如果本地时间小于 expires 设定的过期时间,那么就直接去缓存中取这个资源。由于时间戳是服务器来定义的,而本地时间的取值却来自客户端,因此 expires 的工作机制对客户端时间与服务器时间之间的一致性提出了极高的要求,若服务器与客户端存在时差,将带来意料之外的结果。Cache-Control max-age:cache-control: max-age=31536000Cache-Control中的max-age字段也允许我们通过设定相对的时间长度来达到同样的目的。在 HTTP1.1 标准试图将缓存相关配置收敛进Cache-Control这样的大背景下,max-age可以视作是对 expires 能力的补位/替换。在当下的前端实践里,我们普遍会倾向于使用max-age。
Cache-Control 的 max-age 配置项相对于 expires 的优先级更高。当 Cache-Control 与 expires 同时出现时,我们以 Cache-Control 为准。
Cache-Control其他应用:cache-control: max-age=3600, s-maxage=31536000中s-maxages-maxage优先级高于max-age,两者同时出现时,优先考虑s-maxage。如果s-maxage未过期,则向代理服务器请求其缓存内容。
在依赖各种代理的大型架构中,我们不得不考虑代理服务器的缓存问题。s-maxage 就是用于表示 cache 服务器上(比如 cache CDN)的缓存的有效时间的,并只对 public 缓存有效。
如果我们为资源设置了 public,那么它既可以被浏览器缓存,也可以被代理服务器缓存;如果我们设置了 private,则该资源只能被浏览器缓存。private 为默认值。no-store与no-cache:
no-cache 绕开了浏览器:我们为资源设置了 no-cache 后,每一次发起请求都不会再去询问浏览器的缓存情况,而是直接向服务端去确认该资源是否过期(即走我们下文即将讲解的协商缓存的路线)。no-store 比较绝情,顾名思义就是不使用任何缓存策略。在 no-cache 的基础上,它连服务端的缓存确认也绕开了,只允许你直接向服务端发送请求、并下载完整的响应。
协商缓存:浏览器与服务器合作之下的缓存策略
协商缓存机制下,浏览器需要向服务器去询问缓存的相关信息,进而判断是重新发起请求、下载完整的响应,还是从本地获取缓存的资源。
如果服务端提示缓存资源未改动(Not Modified),资源会被重定向到浏览器缓存,这种情况下网络请求对应的状态码是 304。
协商缓存的实现:从Last-Modified 到 Etag
Last-Modified 是一个时间戳,如果我们启用了协商缓存,它会在首次请求时随着 Response Headers 返回:Last-Modified: Fri, 27 Oct 2017 06:35:57 GMT
随后我们每次请求时,会带上一个叫 If-Modified-Since 的时间戳字段,它的值正是上一次 response 返回给它的 last-modified 值:If-Modified-Since: Fri, 27 Oct 2017 06:35:57 GMT
服务器接收到这个时间戳后,会比对该时间戳和资源在服务器上的最后修改时间是否一致,从而判断资源是否发生了变化。如果发生了变化,就会返回一个完整的响应内容,并在 Response Headers 中添加新的 Last-Modified 值;否则,返回如上图的 304 响应,Response Headers 不会再添加 Last-Modified 字段。协商缓存有缺点:(服务器没有正确感知文件的变化)
我们编辑了文件,但文件的内容没有改变。服务端并不清楚我们是否真正改变了文件,它仍然通过最后编辑时间进行判断。因此这个资源在再次被请求时,会被当做新资源,进而引发一次完整的响应——不该重新请求的时候,也会重新请求。
我们编辑了文件,但文件的内容没有改变。服务端并不清楚我们是否真正改变了文件,它仍然通过最后编辑时间进行判断。因此这个资源在再次被请求时,会被当做新资源,进而引发一次完整的响应——不该重新请求的时候,也会重新请求。
Etag:
Etag 是由服务器为每个资源生成的唯一的标识字符串,这个标识字符串是基于文件内容编码的,只要文件内容不同,它们对应的 Etag 就是不同的,反之亦然。因此 Etag 能够精准地感知文件的变化。
Etag 和 Last-Modified 类似,当首次请求时,我们会在响应头里获取到一个最初的标识符字符串,那么下一次请求时,请求头里就会带上一个值相同的、名为 if-None-Match 的字符串供服务端比对了。
Etag 的生成过程需要服务器额外付出开销,会影响服务端的性能,这是它的弊端。因此启用 Etag 需要我们审时度势。正如我们刚刚所提到的——Etag 并不能替代 Last-Modified,它只能作为 Last-Modified 的补充和强化存在。 Etag 在感知文件变化上比 Last-Modified 更加准确,优先级也更高。当 Etag 和 Last-Modified 同时存在时,以 Etag 为准。
HTTP缓存决策指南:
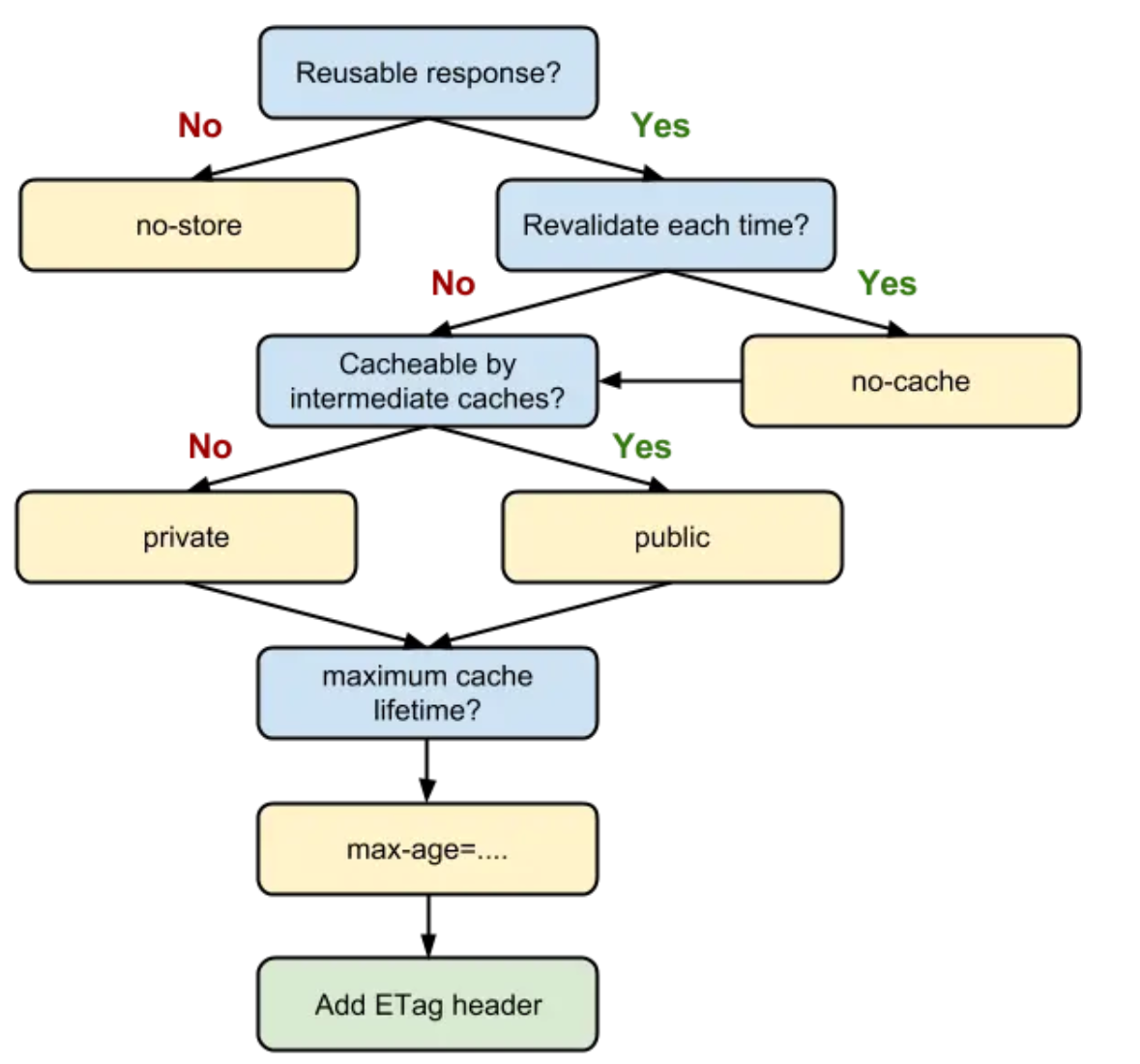
MemoryCache
MemoryCache,是指存在内存中的缓存。从优先级上来说,它是浏览器最先尝试去命中的一种缓存。从效率上来说,它是响应速度最快的一种缓存。
内存缓存是快的,也是“短命”的。它和渲染进程“生死相依”,当进程结束后,也就是 tab 关闭以后,内存里的数据也将不复存在。
那么哪些文件会被放入内存呢?
事实上,这个划分规则,一直以来是没有定论的。不过想想也可以理解,内存是有限的,很多时候需要先考虑即时呈现的内存余量,再根据具体的情况决定分配给内存和磁盘的资源量的比重——资源存放的位置具有一定的随机性。
虽然划分规则没有定论,但根据日常开发中观察的结果,我们至少可以总结出这样的规律:资源存不存内存,浏览器秉承的是“节约原则”。我们发现,Base64 格式的图片,几乎永远可以被塞进 memory cache,这可以视作浏览器为节省渲染开销的“自保行为”;此外,体积不大的 JS、CSS 文件,也有较大地被写入内存的几率——相比之下,较大的 JS、CSS 文件就没有这个待遇了,内存资源是有限的,它们往往被直接甩进磁盘。
Service Worker Cache
Service Worker 是一种独立于主线程之外的 Javascript 线程。它脱离于浏览器窗体,因此无法直接访问 DOM。这样独立的个性使得 Service Worker 的“个人行为”无法干扰页面的性能,这个“幕后工作者”可以帮我们实现离线缓存、消息推送和网络代理等功能。我们借助 Service worker 实现的离线缓存就称为 Service Worker Cache。
Service Worker 的生命周期包括 install、active、working 三个阶段。一旦 Service Worker 被 install,它将始终存在,只会在 active 与 working 之间切换,除非我们主动终止它。这是它可以用来实现离线存储的重要先决条件。
//网页入口文件 使用Service Worker 实现离线缓存
window.navigator.serviceWorker.register('/test.js').then(
function () {
console.log('注册成功')
}).catch(err => {
console.error("注册失败")
})
在 test.js 中,我们进行缓存的处理。假设我们需要缓存的文件分别是 test.html,test.css 和 test.js
// Service Worker会监听 install事件,我们在其对应的回调里可以实现初始化的逻辑
self.addEventListener('install', event => {
event.waitUntil(
// 考虑到缓存也需要更新,open内传入的参数为缓存的版本号
caches.open('test-v1').then(cache => {
return cache.addAll([
// 此处传入指定的需缓存的文件名
'/test.html',
'/test.css',
'/test.js'
])
})
)
})
// Service Worker会监听所有的网络请求,网络请求的产生触发的是fetch事件,我们可以在其对应的监听函数中实现对请求的拦截,进而判断是否有对应到该请求的缓存,实现从Service Worker中取到缓存的目的
self.addEventListener('fetch', event => {
event.respondWith(
// 尝试匹配该请求对应的缓存值
caches.match(event.request).then(res => {
// 如果匹配到了,调用Server Worker缓存
if (res) {
return res;
}
// 如果没匹配到,向服务端发起这个资源请求
return fetch(event.request).then(response => {
if (!response || response.status !== 200) {
return response;
}
// 请求成功的话,将请求缓存起来。
caches.open('test-v1').then(function(cache) {
cache.put(event.request, response);
});
return response.clone();
});
})
);
});
Server Worker 对协议是有要求的,必须以 https 协议为前提。
Push Cache
Push Cache 是缓存的最后一道防线。浏览器只有在 Memory Cache、HTTP Cache 和 Service Worker Cache 均未命中的情况下才会去询问 Push Cache。
Push Cache 是一种存在于会话阶段的缓存,当 session 终止时,缓存也随之释放。
不同的页面只要共享了同一个 HTTP2 连接,那么它们就可以共享同一个 Push Cache。
本地存储——Cookie到Web Storage, IndexDB
Cookie
Cookie 说白了就是一个存储在浏览器里的一个小小的文本文件,它附着在 HTTP 请求上,在浏览器和服务器之间“飞来飞去”。它可以携带用户信息,当服务器检查 Cookie 的时候,便可以获取到客户端的状态。
Cookie有一些的劣势
Cookie不够大,最大只有4KB,超过部分被裁切。
过量Cookie会带来巨大性能浪费。
Cookie是紧跟域名的,通过响应头里的 Set-Cookie 指定要存储的 Cookie 值。默认情况下,domain 被设置为设置 Cookie 页面的主机名。
同一个域名下的所有请求,都会携带 Cookie。Cookie 虽然小,请求却可以有很多,随着请求的叠加,这样的不必要的 Cookie 带来的开销将是无法想象的。
Web Storage
Web Storage 是 HTML5 专门为浏览器存储而提供的数据存储机制。它又分为 Local Storage 与 Session Storage。
Local Storage与Session Storage的区别:
两者的区别在于生命周期与作用域的不同。
生命周期:Local Storage 是持久化的本地存储,存储在其中的数据是永远不会过期的,使其消失的唯一办法是手动删除;而 Session Storage 是临时性的本地存储,它是会话级别的存储,当会话结束(页面被关闭)时,存储内容也随之被释放。
作用域:Local Storage、Session Storage 和 Cookie 都遵循同源策略。但 Session Storage 特别的一点在于,即便是相同域名下的两个页面,只要它们不在同一个浏览器窗口中打开,那么它们的 Session Storage 内容便无法共享。
Web Storage的特性
存储容量大: Web Storage 根据浏览器的不同,存储容量可以达到 5-10M 之间。
仅位于浏览器端,不与服务端发生通信。
Web Storage核心API使用示例
Web Storage 保存的数据内容和 Cookie 一样,是文本内容,以键值对的形式存在。Local Storage 与 Session Storage 在 API 方面无异,这里我们以 localStorage 为例:
存储数据:
localStorage.setItem('user_name', 'xiuyan')读取数据:
localStorage.getItem('user_name')删除数据:
localStorage.removeItem('user_name')清空数据:
localStorage.clear()
应用场景:
Local Storage:
Local Storage 在存储方面没有什么特别的限制,理论上 Cookie 无法胜任的、可以用简单的键值对来存取的数据存储任务,都可以交给 Local Storage 来做。
考虑到 Local Storage 的特点之一是持久,有时我们更倾向于用它来存储一些内容稳定的资源。比如图片内容丰富的电商网站会用它来存储 Base64 格式的图片字符串。有的网站还会用它存储一些不经常更新的 CSS、JS 等静态资源。Session Storage:
Session Storage 更适合用来存储生命周期和它同步的会话级别的信息。这些信息只适用于当前会话,当你开启新的会话时,它也需要相应的更新或释放。比如微博的 Session Storage 就主要是存储你本次会话的浏览足迹。Web Storage 是一个从定义到使用都非常简单的东西。它使用键值对的形式进行存储,这种模式有点类似于对象,却甚至连对象都不是——它只能存储字符串,要想得到对象,我们还需要先对字符串进行一轮解析。
说到底,Web Storage 是对 Cookie 的拓展,它只能用于存储少量的简单数据。当遇到大规模的、结构复杂的数据时,Web Storage 也爱莫能助了。这时候我们就要清楚我们的终极大 boss——IndexedDB!
IndexedDB
IndexedDB 是一个运行在浏览器上的非关系型数据库。既然是数据库了,那就不是 5M、10M 这样小打小闹级别了。理论上来说,IndexedDB 是没有存储上限的(一般来说不会小于 250M)。它不仅可以存储字符串,还可以存储二进制数据。
在 IndexedDB 中,我们可以创建多个数据库,一个数据库中创建多张表,一张表中存储多条数据——这足以 hold 住复杂的结构性数据。IndexedDB 可以看做是 LocalStorage 的一个升级,当数据的复杂度和规模上升到了 LocalStorage 无法解决的程度,我们毫无疑问可以请出 IndexedDB 来帮忙。
打开/创建一个 IndexedDB 数据库(当该数据库不存在时,open 方法会直接创建一个名为 xiaoceDB 新数据库)。
// 后面的回调中,我们可以通过event.target.result拿到数据库实例
let db
// 参数1位数据库名,参数2为版本号
const request = window.indexedDB.open("xiaoceDB", 1)
// 使用IndexedDB失败时的监听函数
request.onerror = function(event) {
console.log('无法使用IndexedDB')
}
// 成功
request.onsuccess = function(event){
// 此处就可以获取到db实例
db = event.target.result
console.log("你打开了IndexedDB")
}
创建一个 object store(object store 对标到数据库中的“表”单位)。
// onupgradeneeded事件会在初始化数据库/版本发生更新时被调用,我们在它的监听函数中创建object store
request.onupgradeneeded = function(event){
let objectStore
// 如果同名表未被创建过,则新建test表
if (!db.objectStoreNames.contains('test')) {
objectStore = db.createObjectStore('test', { keyPath: 'id' })
}
} 构建一个事务来执行一些数据库操作,像增加或提取数据等。
// 创建事务,指定表格名称和读写权限
const transaction = db.transaction(["test"],"readwrite")
// 拿到Object Store对象
const objectStore = transaction.objectStore("test")
// 向表格写入数据
objectStore.add({id: 1, name: 'xiuyan'})
通过监听正确类型的事件以等待操作完成。
// 操作成功时的监听函数
transaction.oncomplete = function(event) {
console.log("操作成功")
}
// 操作失败时的监听函数
transaction.onerror = function(event) {
console.log("这里有一个Error")
}