服务端渲染入门
服务端渲染(SSR)近两年炒得很火热,相信各位同学对这个名词多少有所耳闻。本节我们将围绕“是什么”(服务端渲染的运行机制)、“为什么”(服务端渲染解决了什么性能问题 )、“怎么做”(服务端渲染的应用实例与使用场景)这三个点,对服务端渲染进行探索。
服务端渲染是一个相对的概念,它的对立面是“客户端渲染”。在运行机制解析这部分,我们会借力客户端渲染的概念,来帮大家理解服务端渲染的工作方式。基于对工作方式的了解,再去深挖它的原理与优势。
服务端渲染运行机制
客户端渲染
页面上呈现的内容,你在 html 源文件里里找不到——这正是客户端渲染的特点。
客户端渲染模式下,服务端会把渲染需要的静态文件发送给客户端,客户端加载过来之后,自己在浏览器里跑一遍 JS,根据 JS 的运行结果,生成相应的 DOM。这种特性使得客户端渲染的源代码总是特别简洁,往往是这个德行:
<!doctype html>
<html>
<head>
<title>我是客户端渲染的页面</title>
</head>
<body>
<div id='root'></div>
<script src='index.js'></script>
</body>
</html>
根节点下到底是什么内容呢?你不知道,我不知道,只有浏览器把 index.js 跑过一遍后才知道,这就是典型的客户端渲染。
服务端渲染
服务端返回的 HTML 文件已经是可以直接进行渲染的内容了。
服务端渲染的模式下,当用户第一次请求页面时,由服务器把需要的组件或页面渲染成 HTML 字符串,然后把它返回给客户端。客户端拿到手的,是可以直接渲染然后呈现给用户的 HTML 内容,不需要为了生成 DOM 内容自己再去跑一遍 JS 代码。
使用服务端渲染的网站,可以说是“所见即所得”,页面上呈现的内容,我们在 html 源文件里也能找到。
服务端渲染解决了什么性能问题
网站是出于效益的考虑才启用服务端渲染,性能倒是在其次。
假设 A 网站页面中有一个关键字叫“前端性能优化”,这个关键字是 JS 代码跑过一遍后添加到 HTML 页面中的。那么客户端渲染模式下,我们在搜索引擎搜索这个关键字,是找不到 A 网站的——搜索引擎只会查找现成的内容,不会帮你跑 JS 代码。A 网站的运营方见此情形,感到很头大:搜索引擎搜不出来,用户找不到我们,谁还会用我的网站呢?为了把“现成的内容”拿给搜索引擎看,A 网站不得不启用服务端渲染。
但性能在其次,不代表性能不重要。服务端渲染解决了一个非常关键的性能问题——首屏加载速度过慢。在客户端渲染模式下,我们除了加载 HTML,还要等渲染所需的这部分 JS 加载完,之后还得把这部分 JS 在浏览器上再跑一遍。这一切都是发生在用户点击了我们的链接之后的事情,在这个过程结束之前,用户始终见不到我们网页的庐山真面目,也就是说用户一直在等!相比之下,服务端渲染模式下,服务器给到客户端的已经是一个直接可以拿来呈现给用户的网页,中间环节早在服务端就帮我们做掉了,用户岂不“美滋滋”?
服务端渲染的应用实例
使用 Express 搭建后端服务。
const Vue = require('vue')
// 创建一个express应用
const server = require('express')()
// 提取出renderer实例
const renderer = require('vue-server-renderer').createRenderer()
server.get('*', (req, res) => {
// 编写Vue实例(虚拟DOM节点)
const app = new Vue({
data: {
url: req.url
},
// 编写模板HTML的内容
template: `<div>访问的 URL 是: {{ url }}</div>`
})
// renderToString 是把Vue实例转化为真实DOM的关键方法
renderer.renderToString(app, (err, html) => {
if (err) {
res.status(500).end('Internal Server Error')
return
}
// 把渲染出来的真实DOM字符串插入HTML模板中
res.end(`
<!DOCTYPE html>
<html lang="en">
<head><title>Hello</title></head>
<body>${html}</body>
</html>
`)
})
})
server.listen(8080)
强调的只有两点:一是这个 renderToString() 方法;二是把转化结果“塞”进模板里的这一步。这两个操作是服务端渲染的灵魂操作。在虚拟 DOM“横行”的当下,服务端渲染不再是早年 JSP 里简单粗暴的字符串拼接过程,它还要求这一端要具备将虚拟 DOM 转化为真实 DOM 的能力。与其说是“把 JS 在服务器上先跑一遍”,不如说是“把 Vue、React 等框架代码先在 Node 上跑一遍”。
服务端渲染的应用场景
服务端渲染本质上是本该浏览器做的事情,分担给服务器去做。这样当资源抵达浏览器时,它呈现的速度就快了。乍一看好像很合理:浏览器性能毕竟有限,服务器多牛逼!能者多劳,就该让服务器多干点活!
但仔细想想,在这个网民遍地的时代,几乎有多少个用户就有多少台浏览器。用户拥有的浏览器总量多到数不清,那么一个公司的服务器又有多少台呢?我们把这么多台浏览器的渲染压力集中起来,分散给相比之下数量并不多的服务器,服务器肯定是承受不住的。
这样分析下来,服务端渲染也并非万全之策。在实践中,服务器稀少而宝贵,但首屏渲染体验和 SEO 的优化方案却很多——我们最好先把能用的低成本“大招”都用完。除非网页对性能要求太高了,以至于所有的招式都用完了,性能表现还是不尽人意,这时候我们就可以考虑把服务端渲染搞起来了。
浏览器运行机制
浏览器内核
浏览器内核决定了浏览器解释网页语法的方式。
浏览器内核可以分成两部分:渲染引擎(Layout Engine 或者 Rendering Engine)和 JS 引擎。早期渲染引擎和 JS 引擎并没有十分明确的区分,但随着 JS 引擎越来越独立,内核也成了渲染引擎的代称。渲染引擎又包括了 HTML 解释器、CSS 解释器、布局、网络、存储、图形、音视频、图片解码器等等零部件。
目前市面上常见的浏览器内核可以分为这四种:Trident(IE)、Gecko(火狐)、Blink(Chrome、Opera)、Webkit(Safari)
浏览器渲染过程

最需要关注的是HTML 解释器、CSS 解释器、图层布局计算模块、视图绘制模块与JavaScript 引擎这几大模块:
HTML 解释器:将 HTML 文档经过词法分析输出 DOM 树。
CSS 解释器:解析 CSS 文档, 生成样式规则。
图层布局计算模块:布局计算每个对象的精确位置和大小。
视图绘制模块:进行具体节点的图像绘制,将像素渲染到屏幕上。
JavaScript 引擎:编译执行 Javascript 代码。
浏览器渲染过程解析

解析 HTML
在这一步浏览器执行了所有的加载解析逻辑,在解析 HTML 的过程中发出了页面渲染所需的各种外部资源请求。
计算样式
浏览器将识别并加载所有的 CSS 样式信息与 DOM 树合并,最终生成页面 render 树(:after :before 这样的伪元素会在这个环节被构建到 DOM 树中)。
计算图层布局
页面中所有元素的相对位置信息,大小等信息均在这一步得到计算。
绘制图层
在这一步中浏览器会根据我们的 DOM 代码结果,把每一个页面图层转换为像素,并对所有的媒体文件进行解码。
整合图层,得到页面
最后一步浏览器会合并合各个图层,将数据由 CPU 输出给 GPU 最终绘制在屏幕上。(复杂的视图层会给这个阶段的 GPU 计算带来一些压力,在实际应用中为了优化动画性能,我们有时会手动区分不同的图层)。
几颗重要的树
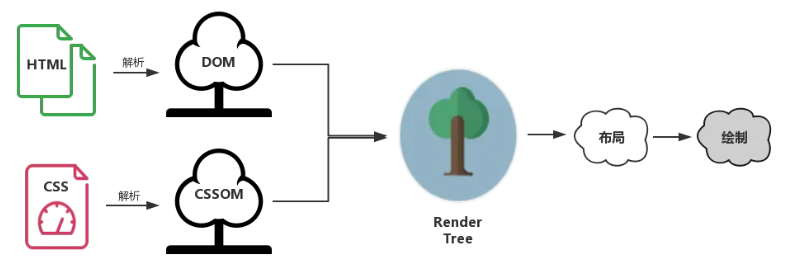
DOM 树:解析 HTML 以创建的是 DOM 树(DOM tree ):渲染引擎开始解析 HTML 文档,转换树中的标签到 DOM 节点,它被称为“内容树”。
CSSOM 树:解析 CSS(包括外部 CSS 文件和样式元素)创建的是 CSSOM 树。CSSOM 的解析过程与 DOM 的解析过程是并行的。
渲染树:CSSOM 与 DOM 结合,之后我们得到的就是渲染树(Render tree )。
布局渲染树:从根节点递归调用,计算每一个元素的大小、位置等,给每个节点所应该出现在屏幕上的精确坐标,我们便得到了基于渲染树的布局渲染树(Layout of the render tree)。
绘制渲染树: 遍历渲染树,每个节点将使用 UI 后端层来绘制。整个过程叫做绘制渲染树(Painting the render tree)。
渲染过程说白了,首先是基于 HTML 构建一个 DOM 树,这棵 DOM 树与 CSS 解释器解析出的 CSSOM 相结合,就有了布局渲染树。最后浏览器以布局渲染树为蓝本,去计算布局并绘制图像,我们页面的初次渲染就大功告成了。
之后每当一个新元素加入到这个 DOM 树当中,浏览器便会通过 CSS 引擎查遍 CSS 样式表,找到符合该元素的样式规则应用到这个元素上,然后再重新去绘制它。
基于渲染流程的CSS优化建议
CSS 引擎查找样式表,对每条规则都按从右到左的顺序去匹配。
#myList li {} 事实上,CSS 选择符是从右到左进行匹配的。浏览器必须遍历页面上每个 li 元素,并且每次都要去确认这个 li 元素的父元素 id 是不是 myList。
根据上面的分析,我们至少可以总结出如下性能提升的方案:
避免使用通配符,只对需要用到的元素进行选择。
关注可以通过继承实现的属性,避免重复匹配重复定义。
少用标签选择器。如果可以,用类选择器替代。
减少嵌套。后代选择器的开销是最高的,因此我们应该尽量将选择器的深度降到最低(最高不要超过三层),尽可能使用类来关联每一个标签元素。
CSS与JS的加载顺序优化
HTML、CSS 和 JS,都具有阻塞渲染的特性。
HTML 阻塞,天经地义——没有 HTML,何来 DOM?没有 DOM,渲染和优化,都是空谈。
CSS的阻塞
默认情况下,CSS 是阻塞的资源。浏览器在构建 CSSOM 的过程中,不会渲染任何已处理的内容。即便 DOM 已经解析完毕了,只要 CSSOM 不 OK,那么渲染这个事情就不 OK(这主要是为了避免没有 CSS 的 HTML 页面丑陋地“裸奔”在用户眼前)。只有当我们开始解析 HTML 后、解析到 link 标签或者 style 标签时,CSS 才登场,CSSOM 的构建才开始。很多时候,DOM 不得不等待 CSSOM。因此我们可以这样总结:
CSS 是阻塞渲染的资源。需要将它尽早、尽快地下载到客户端,以便缩短首次渲染的时间。
尽早(将 CSS 放在 head 标签里)和尽快(启用 CDN 实现静态资源加载速度的优化)。这个“把 CSS 往前放”的动作,对很多同学来说已经内化为一种编码习惯。那么现在我们还应该知道,这个“习惯”不是空穴来风,它是由 CSS 的特性决定的。
JS的阻塞
首次渲染过程中,JS 并不是一个非登场不可的角色——没有 JS,CSSOM 和 DOM 照样可以组成渲染树,页面依然会呈现——即使它死气沉沉、毫无交互。
JS 的作用在于修改,它帮助我们修改网页的方方面面:内容、样式以及它如何响应用户交互。这“方方面面”的修改,本质上都是对 DOM 和 CSSDOM 进行修改。因此 JS 的执行会阻止 CSSOM,在我们不作显式声明的情况下,它也会阻塞 DOM。
JS 引擎是独立于渲染引擎存在的。我们的 JS 代码在文档的何处插入,就在何处执行。当 HTML 解析器遇到一个 script 标签时,它会暂停渲染过程,将控制权交给 JS 引擎。JS 引擎对内联的 JS 代码会直接执行,对外部 JS 文件还要先获取到脚本、再进行执行。等 JS 引擎运行完毕,浏览器又会把控制权还给渲染引擎,继续 CSSOM 和 DOM 的构建。 因此与其说是 JS 把 CSS 和 HTML 阻塞了,不如说是 JS 引擎抢走了渲染引擎的控制权。
浏览器之所以让 JS 阻塞其它的活动,是因为它不知道 JS 会做什么改变,担心如果不阻止后续的操作,会造成混乱。但是我们是写 JS 的人,我们知道 JS 会做什么改变。假如我们可以确认一个 JS 文件的执行时机并不一定非要是此时此刻,我们就可以通过对它使用 defer 和 async 来避免不必要的阻塞,这里我们就引出了外部 JS 的三种加载方式。
JS的三种加载方式
正常模式:
<script src="index.js"></script>这种情况下 JS 会阻塞浏览器,浏览器必须等待 index.js 加载和执行完毕才能去做其它事情。
async 模式:
hasync 模式下,JS 不会阻塞浏览器做任何其它的事情。它的加载是异步的,当它加载结束,JS 脚本会立即执行。
defer 模式:
<script defer src="index.js"></script>defer 模式下,JS 的加载是异步的,执行是被推迟的。等整个文档解析完成、DOMContentLoaded 事件即将被触发时,被标记了 defer 的 JS 文件才会开始依次执行。
一般当我们的脚本与 DOM 元素和其它脚本之间的依赖关系不强时,我们会选用 async;当脚本依赖于 DOM 元素和其它脚本的执行结果时,我们会选用 defer。
通过审时度势地向 script 标签添加 async/defer,我们就可以告诉浏览器在等待脚本可用期间不阻止其它的工作,这样可以显著提升性能。
DOM优化原理与实践
DOM为什么这么慢
有过路费
S 是很快的,在 JS 中修改 DOM 对象也是很快的。在JS的世界里,一切是简单的、迅速的。但 DOM 操作并非 JS 一个人的独舞,而是两个模块之间的协作。
上一节我们提到,JS 引擎和渲染引擎(浏览器内核)是独立实现的。当我们用 JS 去操作 DOM 时,本质上是 JS 引擎和渲染引擎之间进行了“跨界交流”。这个“跨界交流”的实现并不简单。
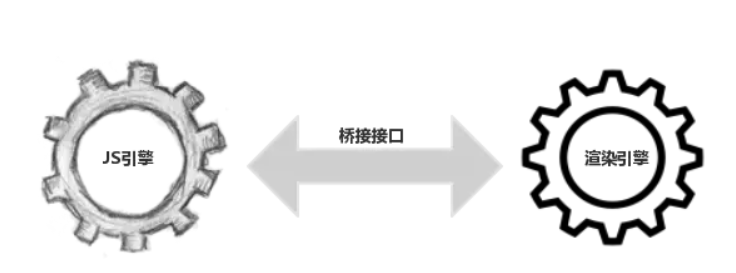
过“桥”要收费——这个开销本身就是不可忽略的。我们每操作一次 DOM(不管是为了修改还是仅仅为了访问其值),都要过一次“桥”。过“桥”的次数一多,就会产生比较明显的性能问题。因此“减少 DOM 操作”的建议,并非空穴来风。
对 DOM 的修改引发样式的更迭
我们对 DOM 的操作都不会局限于访问,而是为了修改它。当我们对 DOM 的修改会引发它外观(样式)上的改变时,就会触发回流或重绘。这个过程本质上还是因为我们对 DOM 的修改触发了渲染树(Render Tree)的变化所导致的
回流:当我们对 DOM 的修改引发了 DOM 几何尺寸的变化(比如修改元素的宽、高或隐藏元素等)时,浏览器需要重新计算元素的几何属性(其他元素的几何属性和位置也会因此受到影响),然后再将计算的结果绘制出来。这个过程就是回流(也叫重排)。
重绘:当我们对 DOM 的修改导致了样式的变化、却并未影响其几何属性(比如修改了颜色或背景色)时,浏览器不需重新计算元素的几何属性、直接为该元素绘制新的样式(跳过了上图所示的回流环节)。这个过程叫做重绘。
重绘不一定导致回流,回流一定会导致重绘。硬要比较的话,回流比重绘做的事情更多,带来的开销也更大。但这两个说到底都是吃性能的,所以都不是什么善茬。我们在开发中,要从代码层面出发,尽可能把回流和重绘的次数最小化。
DOM提速
减少DOM操作,少交过路费,避免过度渲染。
JS 层面的事情,JS 自己去处理,处理好了,再来找 DOM 打报告。
此时我有一个假需求——我想往 container 元素里写 10000 句一样的话。如果我这么做:
for(var count=0;count<10000;count++){
document.getElementById('container').innerHTML+='<span>我是一个小测试</span>'
} 这段代码有两个明显的可优化点。
第一点,过路费交太多了。我们每一次循环都调用 DOM 接口重新获取了一次 container 元素,相当于每次循环都交了一次过路费。前后交了 10000 次过路费,但其中 9999 次过路费都可以用缓存变量的方式节省下来:
// 只获取一次container
let container = document.getElementById('container')
for(let count=0;count<10000;count++){
container.innerHTML += '<span>我是一个小测试</span>'
}
第二点,不必要的 DOM 更改太多了。我们的 10000 次循环里,修改了 10000 次 DOM 树。我们前面说过,对 DOM 的修改会引发渲染树的改变、进而去走一个(可能的)回流或重绘的过程,而这个过程的开销是很“贵”的。这么贵的操作,我们竟然重复执行了 N 多次!其实我们可以通过就事论事的方式节省下来不必要的渲染:
let container = document.getElementById('container')
let content = ''
for(let count=0;count<10000;count++){
// 先对内容进行操作
content += '<span>我是一个小测试</span>'
}
// 内容处理好了,最后再触发DOM的更改
container.innerHTML = content
考虑JS 的运行速度,比 DOM 快得多这个特性。我们减少 DOM 操作的核心思路,就是让 JS 去给 DOM 分压。
这个思路,在 DOM Fragment 中体现得淋漓尽致。
DocumentFragment 接口表示一个没有父级文件的最小文档对象。它被当做一个轻量版的 Document 使用,用于存储已排好版的或尚未打理好格式的XML片段。因为 DocumentFragment 不是真实 DOM 树的一部分,它的变化不会引起 DOM 树的重新渲染的操作(reflow),且不会导致性能等问题。
在我们上面的例子里,字符串变量 content 就扮演着一个 DOM Fragment 的角色。其实无论字符串变量也好,DOM Fragment 也罢,它们本质上都作为脱离了真实 DOM 树的容器出现,用于缓存批量化的 DOM 操作。
前面我们直接用 innerHTML 去拼接目标内容,这样做固然有用,但却不够优雅。相比之下,DOM Fragment 可以帮助我们用更加结构化的方式去达成同样的目的,从而在维持性能的同时,保住我们代码的可拓展和可维护性。我们现在用 DOM Fragment 来改写上面的例子:
let container = document.getElementById('container')
// 创建一个DOM Fragment对象作为容器
let content = document.createDocumentFragment()
for(let count=0;count<10000;count++){
// span此时可以通过DOM API去创建
let oSpan = document.createElement("span")
oSpan.innerHTML = '我是一个小测试'
// 像操作真实DOM一样操作DOM Fragment对象
content.appendChild(oSpan)
}
// 内容处理好了,最后再触发真实DOM的更改
container.appendChild(content)
DOM Fragment 对象允许我们像操作真实 DOM 一样去调用各种各样的 DOM API,我们的代码质量因此得到了保证。并且它的身份也非常纯粹:当我们试图将其 append 进真实 DOM 时,它会在乖乖交出自身缓存的所有后代节点后全身而退,完美地完成一个容器的使命,而不会出现在真实的 DOM 结构中。这种结构化、干净利落的特性,使得 DOM Fragment 作为经典的性能优化手段大受欢迎,这一点在 jQuery、Vue 等优秀前端框架的源码中均有体现。
EventLoop与异步更新策略
Event Loop 中的“渲染时机”
Micro-Task与Macro-Task
事件循环中的异步队列有两种:macro(宏任务)队列和 micro(微任务)队列。
常见的 macro-task 比如: setTimeout、setInterval、 setImmediate、script(整体代码)、 I/O 操作、UI 渲染等。
常见的 micro-task 比如: process.nextTick、Promise、MutationObserver 等。
Event Loop过程解析
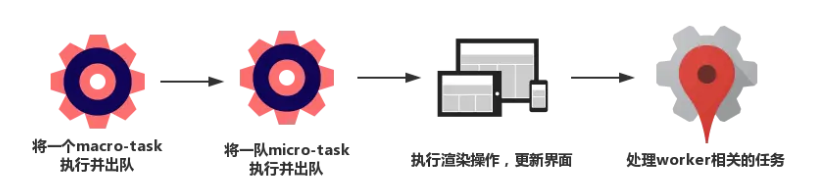
一个完整的 Event Loop 过程,可以概括为以下阶段:
初始状态:调用栈空。micro 队列空,macro 队列里有且只有一个 script 脚本(整体代码)。
全局上下文(script 标签)被推入调用栈,同步代码执行。在执行的过程中,通过对一些接口的调用,可以产生新的 macro-task 与 micro-task,它们会分别被推入各自的任务队列里。同步代码执行完了,script 脚本会被移出 macro 队列,这个过程本质上是队列的 macro-task 的执行和出队的过程。
上一步我们出队的是一个 macro-task,这一步我们处理的是 micro-task。但需要注意的是:当 macro-task 出队时,任务是一个一个执行的;而 micro-task 出队时,任务是一队一队执行的(如下图所示)。因此,我们处理 micro 队列这一步,会逐个执行队列中的任务并把它出队,直到队列被清空。
执行渲染操作,更新界面(敲黑板划重点)。
检查是否存在 Web worker 任务,如果有,则对其进行处理 。
上述过程循环往复,直到两个队列都清空每一次循环都是一个这样的过程:
渲染的时机
假如我想要在异步任务里进行DOM更新,我该把它包装成 micro 还是 macro 呢?
我们先假设它是一个 macro 任务,比如我在 script 脚本中用 setTimeout 来处理它:
// task是一个用于修改DOM的回调
setTimeout(task, 0)现在 task 被推入的 macro 队列。但因为 script 脚本本身是一个 macro 任务,所以本次执行完 script 脚本之后,下一个步骤就要去处理 micro 队列了,再往下就去执行了一次 render,对不对?
但本次render我的目标task其实并没有执行,想要修改的DOM也没有修改,因此这一次的render其实是一次无效的render。
转向 micro 试试看。我用 Promise 来把 task 包装成是一个 micro 任务:
Promise.resolve().then(task)那么我们结束了对 script 脚本的执行,是不是紧接着就去处理 micro-task 队列了?micro-task 处理完,DOM 修改好了,紧接着就可以走 render 流程了——不需要再消耗多余的一次渲染,不需要再等待一轮事件循环,直接为用户呈现最即时的更新结果。
因此,我们更新 DOM 的时间点,应该尽可能靠近渲染的时机。当我们需要在异步任务中实现 DOM 修改时,把它包装成 micro 任务是相对明智的选择。
生产实践:异步更新策略
当我们使用 Vue 或 React 提供的接口去更新数据时,这个更新并不会立即生效,而是会被推入到一个队列里。待到适当的时机,队列中的更新任务会被批量触发。这就是异步更新。
异步更新可以帮助我们避免过度渲染,是我们上节提到的“让 JS 为 DOM 分压”的典范之一。
异步更新的优越性
异步更新的特性在于它只看结果,因此渲染引擎不需要为过程买单。
我们在三个更新任务中对同一个状态修改了三次,如果我们采取传统的同步更新策略,那么就要操作三次 DOM。但本质上需要呈现给用户的目标内容其实只是第三次的结果,也就是说只有第三次的操作是有意义的——我们白白浪费了两次计算。
但如果我们把这三个任务塞进异步更新队列里,它们会先在 JS 的层面上被批量执行完毕。当流程走到渲染这一步时,它仅仅需要针对有意义的计算结果操作一次 DOM——这就是异步更新的妙处。
Vue状态更新手法:nextTick
Vue 每次想要更新一个状态的时候,会先把它这个更新操作给包装成一个异步操作派发出去。这件事情,在源码中是由一个叫做 nextTick 的函数来完成的:
export function nextTick (cb?: Function, ctx?: Object) {
let _resolve
callbacks.push(() => {
if (cb) {
try {
cb.call(ctx)
} catch (e) {
handleError(e, ctx, 'nextTick')
}
} else if (_resolve) {
_resolve(ctx)
}
})
// 检查上一个异步任务队列(即名为callbacks的任务数组)是否派发和执行完毕了。pending此处相当于一个锁
if (!pending) {
// 若上一个异步任务队列已经执行完毕,则将pending设定为true(把锁锁上)
pending = true
// 是否要求一定要派发为macro任务
if (useMacroTask) {
macroTimerFunc()
} else {
// 如果不说明一定要macro 你们就全都是micro
microTimerFunc()
}
}
// $flow-disable-line
if (!cb && typeof Promise !== 'undefined') {
return new Promise(resolve => {
_resolve = resolve
})
}
}Vue 的异步任务默认情况下都是用 Promise 来包装的,也就是是说它们都是 micro-task。这一点和我们“前置知识”中的渲染时机的分析不谋而合。
为了带大家熟悉一下常见的 macro 和 micro 派发方式、加深对 Event Loop 的理解,我们继续细化解析一下 macroTimeFunc() 和 microTimeFunc() 两个方法。
macroTimeFunc() 是这么实现的:
// macro首选setImmediate 这个兼容性最差
if (typeof setImmediate !== 'undefined' && isNative(setImmediate)) {
macroTimerFunc = () => {
setImmediate(flushCallbacks)
}
} else if (typeof MessageChannel !== 'undefined' && (
isNative(MessageChannel) ||
// PhantomJS
MessageChannel.toString() === '[object MessageChannelConstructor]'
)) {
const channel = new MessageChannel()
const port = channel.port2
channel.port1.onmessage = flushCallbacks
macroTimerFunc = () => {
port.postMessage(1)
}
} else {
// 兼容性最好的派发方式是setTimeout
macroTimerFunc = () => {
setTimeout(flushCallbacks, 0)
}
}microTimeFunc() 是这么实现的:
// 简单粗暴 不是ios全都给我去Promise 如果不兼容promise 那么你只能将就一下变成macro了
if (typeof Promise !== 'undefined' && isNative(Promise)) {
const p = Promise.resolve()
microTimerFunc = () => {
p.then(flushCallbacks)
// in problematic UIWebViews, Promise.then doesn't completely break, but
// it can get stuck in a weird state where callbacks are pushed into the
// microtask queue but the queue isn't being flushed, until the browser
// needs to do some other work, e.g. handle a timer. Therefore we can
// "force" the microtask queue to be flushed by adding an empty timer.
if (isIOS) setTimeout(noop)
}
} else {
// 如果无法派发micro,就退而求其次派发为macro
microTimerFunc = macroTimerFunc
}我们注意到,无论是派发 macro 任务还是派发 micro 任务,派发的任务对象都是一个叫做 flushCallbacks 的东西,这个东西做了什么呢?
flushCallbacks 源码如下:
function flushCallbacks () {
pending = false
// callbacks在nextick中出现过 它是任务数组(队列)
const copies = callbacks.slice(0)
callbacks.length = 0
// 将callbacks中的任务逐个取出执行
for (let i = 0; i < copies.length; i++) {
copies[i]()
}
}Vue 中每产生一个状态更新任务,它就会被塞进一个叫 callbacks 的数组(此处是任务队列的实现形式)中。这个任务队列在被丢进 micro 或 macro 队列之前,会先去检查当前是否有异步更新任务正在执行(即检查 pending 锁)。如果确认 pending 锁是开着的(false),就把它设置为锁上(true),然后对当前 callbacks 数组的任务进行派发(丢进 micro 或 macro 队列)和执行。设置 pending 锁的意义在于保证状态更新任务的有序进行,避免发生混乱。
回流与重绘
回流:当我们对 DOM 的修改引发了 DOM 几何尺寸的变化(比如修改元素的宽、高或隐藏元素等)时,浏览器需要重新计算元素的几何属性(其他元素的几何属性和位置也会因此受到影响),然后再将计算的结果绘制出来。这个过程就是回流(也叫重排)。
重绘:当我们对 DOM 的修改导致了样式的变化、却并未影响其几何属性(比如修改了颜色或背景色)时,浏览器不需重新计算元素的几何属性、直接为该元素绘制新的样式(跳过了上图所示的回流环节)。这个过程叫做重绘。
哪些实际操作会导致回流与重绘
要避免回流与重绘的发生,最直接的做法是避免掉可能会引发回流与重绘的 DOM 操作,就好像拆弹专家在解决一颗炸弹时,最重要的是掐灭它的导火索。
触发重绘的“导火索”比较好识别——只要是不触发回流,但又触发了样式改变的 DOM 操作,都会引起重绘,比如背景色、文字色、可见性(可见性这里特指形如visibility: hidden这样不改变元素位置和存在性的、单纯针对可见性的操作,注意与display:none进行区分)等。为此,我们要着重理解一下那些可能触发回流的操作。
回流的导火索
最“贵”的操作:改变 DOM 元素的几何属性
这个改变几乎可以说是“牵一发动全身”——当一个DOM元素的几何属性发生变化时,所有和它相关的节点(比如父子节点、兄弟节点等)的几何属性都需要进行重新计算,它会带来巨大的计算量。
常见的几何属性有 width、height、padding、margin、left、top、border 等等。
“价格适中”的操作:改变 DOM 树的结构
这里主要指的是节点的增减、移动等操作。浏览器引擎布局的过程,顺序上可以类比于树的前序遍历——它是一个从上到下、从左到右的过程。通常在这个过程中,当前元素不会再影响其前面已经遍历过的元素。
最容易被忽略的操作:获取一些特定属性的值
当你要用到像这样的属性:offsetTop、offsetLeft、 offsetWidth、offsetHeight、scrollTop、scrollLeft、scrollWidth、scrollHeight、clientTop、clientLeft、clientWidth、clientHeight 时,你就要注意了!
“像这样”的属性,到底是像什么样?——这些值有一个共性,就是需要通过即时计算得到。因此浏览器为了获取这些值,也会进行回流。
如何规避回流与重绘
将导火索缓存起来,避免频繁改动
<script>
// 获取el元素
const el = document.getElementById('el')
// 这里循环判定比较简单,实际中或许会拓展出比较复杂的判定需求
for(let i=0;i<10;i++) {
el.style.top = el.offsetTop + 10 + "px";
el.style.left = el.offsetLeft + 10 + "px";
}
</script>这样做,每次循环都需要获取多次“敏感属性”,是比较糟糕的。我们可以将其以 JS 变量的形式缓存起来,待计算完毕再提交给浏览器发出重计算请求:
// 缓存offsetLeft与offsetTop的值
const el = document.getElementById('el')
let offLeft = el.offsetLeft, offTop = el.offsetTop
// 在JS层面进行计算
for(let i=0;i<10;i++) {
offLeft += 10
offTop += 10
}
// 一次性将计算结果应用到DOM上
el.style.left = offLeft + "px"
el.style.top = offTop + "px"避免逐条改变样式,使用类名去合并样式
const container = document.getElementById('container')
container.style.width = '100px'
container.style.height = '200px'
container.style.border = '10px solid red'
container.style.color = 'red'优化成一个有 class 加持的样子:
h前者每次单独操作,都去触发一次渲染树更改,从而导致相应的回流与重绘过程。
合并之后,等于我们将所有的更改一次性发出,用一个 style 请求解决掉了。
将DOM离线
我们上文所说的回流和重绘,都是在“该元素位于页面上”的前提下会发生的。一旦我们给元素设置 display: none,将其从页面上“拿掉”,那么我们的后续操作,将无法触发回流与重绘——这个将元素“拿掉”的操作,就叫做 DOM 离线化。
const container = document.getElementById('container')
container.style.width = '100px'
container.style.height = '200px'
container.style.border = '10px solid red'
container.style.color = 'red'
...(省略了许多类似的后续操作)离线化后就是这样:
let container = document.getElementById('container')
container.style.display = 'none'
container.style.width = '100px'
container.style.height = '200px'
container.style.border = '10px solid red'
container.style.color = 'red'
...(省略了许多类似的后续操作)
container.style.display = 'block'拿掉一个元素再把它放回去,这不也会触发一次昂贵的回流吗?这话不假,但我们把它拿下来了,后续不管我操作这个元素多少次,每一步的操作成本都会非常低。当我们只需要进行很少的 DOM 操作时,DOM 离线化的优越性确实不太明显。一旦操作频繁起来,这“拿掉”和“放回”的开销都将会是非常值得的。
Flush队列
现代浏览器是很聪明的。浏览器自己也清楚,如果每次 DOM 操作都即时地反馈一次回流或重绘,那么性能上来说是扛不住的。于是它自己缓存了一个 flush 队列,把我们触发的回流与重绘任务都塞进去,待到有空时(也就是JavaScript 执行栈清空时),或者“不得已”的时候,再将这些任务一口气出队。
前面我们在介绍回流的“导火索”的时候,提到过有一类属性很特别,它们有很强的“即时性”。当我们访问这些属性时,浏览器会为了获得此时此刻的、最准确的属性值,而提前将 flush 队列的任务出队——这就是所谓的“不得已”时刻。具体是哪些属性值,我们已经在“最容易被忽略的操作”这个小模块介绍过了,此处不再赘述。